We are aware that the decision process for a large conference like COLING can be quite opaque from the point of view of authors, especially those who have not served in the role of AC or PC in the past. In this post, we aim to demystify a bit what we are doing (and why it takes so long from submission to decision!). As always, our belief is that more transparency leads to a better process—as we are committed to doing what we lay out, and what we lay out should be justified in this writing—and to a better understanding of the outcomes.
Timeline
Many of our authors are probably aware that reviews were due on April 10, and reviews are seen as the primary determinant of acceptance, so you might well wonder why you won’t be hearing about acceptance decisions until May 17. What could possibly take so long?
We (the PC co-chairs) met in Seattle last July to lay out a detailed timeline, making sure to build in time for careful decision making and also to allow for buffers to handle the near-certainty that some things would go wrong. The portion between April 10 and May 17 looks like this:
| April 10 |
Reviews due |
| April 11 |
ACs request reviewer discussion, chase missing reviews |
| April 15 |
Reviewer discussion ends |
| April 16 |
ACs request fixes to problematic reviews (too short, inappropriate tone) |
| April 19 |
Deadline for reviews to be updated based on AC feedback |
| April 20 |
Reviews available to authors; author response begins |
| April 25 |
Author response ends |
| April 26 |
AC discussion starts |
| May 3 |
Reviewer identities revealed to co-reviewers |
| May 4 |
AC recommendations due to PC co-chairs |
| May 16 |
Signatures revealed for signed reviews |
| May 17 |
Acceptance notifications |
As you can see, the time between the initial deadline for reviews and the final acceptance notification is largely dedicated to two things: making sure all reviews are present and appropriate, and leaving time for thoughtful consideration by both ACs and PC co-chairs in the decision making process.
Of course, not everything goes according to plan. As of April 25, we still have a handful of missing or incomplete reviews. In many of these cases, ACs (including our Special Cirumstances ACs) are stepping in to provide the missing reviews. That this can be done blind is another benefit of keeping author identity from the ACs! (It’s not quite double blind, as authors can probably work out who the ACs are for their track, but that direction is less critical in this case.)
How did we end up with missing reviews? In some cases, this was not the fault of the reviewers at all. There were a handful of cases where START had the wrong email addresses for committee members, and we only discovered this when the ACs emailed the committee members from outside START—only to discover they hadn’t received their assignments! In other cases, committee members agreed to review and submitted bids and then didn’t turn in their reviews. While we absolutely understand that things come up, in the case that someone can’t complete their reviewing assignment, the best course of action in terms of minimizing impact on others (authors, other reviewers asked to step in, and the ACs/PCs managing the process) is just to communicate this fact as soon as possible.
Instructions to ACs
In our very first post to this PC blog we laid out our goals for the COLING 2018 program:
Our goals for COLING 2018 are (1) to create a program of high quality papers which represent diverse approaches to and applications of computational linguistics written and presented by researchers from throughout our international community; (2) to facilitate thoughtful reviewing which is both informative to ACs (and to us as PC co-chairs) and helpful to authors; and (3) to ensure that the results published at COLING 2018 are as reproducible as possible.
The process by which reviews are turned into acceptance decisions is a key part of the first of those goals (but not the only part—recruiting a strong, diverse pool of submissions was a key first step, as well as the design of the review process). Accordingly, these are the directions we have given to ACs, as they consider each paper in their area:
Please, please do not simply rank papers by overall score. Three reviewers is just not enough to get a reliable estimate of a paper’s quality. Maybe one reviewer didn’t read the paper, another one didn’t understand it and reacted poorly, and a final reviewer always gives negative scores; maybe one reviewer as warped priorities and another doesn’t know the area as well. There’s too much individual variance for a tiny number of reviewers (i.e. 3) to precisely judge a paper.
In fact, don’t even sort papers like this to start out with; glancing at that list will unconsciously bias perception of the papers and that’ll mean poor decisions. Save yourself - don’t let knowledge of that ranking make a nuanced review go unread.
However, as an area chair, you know your area well, and have good ideas of the technical merits of individual works in that area. You should be understand the technical content when needed and be able to judge the reviews’ quality for yourself. Once the scores are in, you’ll also have a good idea of which reviewers generally grade low (or high).
Try to order the papers in such a way that the ones you like most at the top, the ones that shouldn’t appear are at the bottom, and each paper is more preferable than the one below. You can split this work with your co-AC as you prefer; some will take half the papers and then merge, but if you do this, it’s important to realise that the split won’t be perfect - you won’t be able to interleave the resulting ranking one-by-one. In any event, both you and your co-AC must explicitly agree on the final ranking.
Use the reviews and author feedback as the evidence for the ranking, and be sure and confident about every decision. If you’re not yet confident, there are a few options. Ask the reviewers to clarify, or to examine a point; ask your co-AC for their opinion; find another reviewer for an extra opinion, if this can be done quickly; or ask us to send over resources.
Once you have an ordering, think about which of that set you’d recommend for acceptance, and send us the rankings along with your recommendations. You should also build a short report on your area - the process and the trends you saw there. Between you and your co-chair, this should be around 100-500 words.
As you can see, we are emphasizing holistic understanding of the merits of each paper, and de-emphasizing the numerical scores. Which brings up the obvious question: Why not rely on the scores?
It’s not just about the scores
Scoring is far too unreliable to be used as acceptance recommendation. We have only three reviewers, each biased in their own way. You won’t get good statistics with a population of 3, and we don’t expect to. This isn’t the reviewer’s fault; it’s just plain statistics. Rather, each review has to be considered on its own—in terms of overall bias, expertise, and how well a paper was understood by them.
So, in the words of Jason Eisner, from his fantastic “How to Serve as Program Chair of a Conference” guide:
How not to do it: Please, please, please don’t just sort the papers by the 3 reviewers’ average overall recommendation! There is too much variance in these scores for n=3 to be a large enough sample. Maybe reviewer #1 tends to give high scores to everyone, reviewer #2 has warped priorities, and reviewer #3 barely read the paper or barely knows the area. Whereas another paper drew a different set of 3 reviewers.
How still not to do it: Even as a first step, don’t sort the papers by average recommendation. Trust me — this noisy and uncalibrated ranking isn’t even a good way to triage the papers into likely accepts, likely rejects, and borderline papers that deserve a closer look. Don’t risk letting it subtly influence the final decisions, or letting it doom some actual, nuanced reviews to go unread.
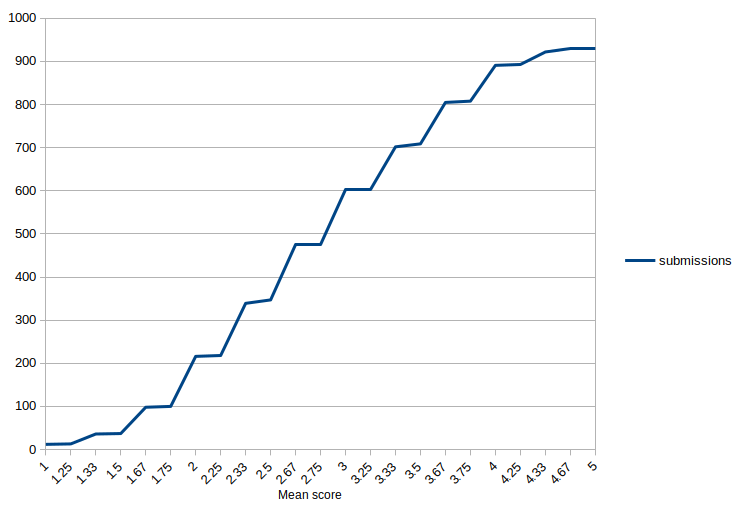
What I told myself: When you’re working with several hundred papers, a single paper with an average score of 3.8 may seem to merit only a shrug and a coin flip. But a single false negative might harm a poor student’s confidence, delay her progress to her next project, or undermine her advisor’s grant proposal or promotion case. Conversely, a single false positive wastes the time of quite a lot of people in your audience.
To do this step fairly, then, for the 872 papers remaining undecided, requires a considerable effort.
The dual role of peer reviewed conferences
As we (the PC co-chairs) work to oversee this process and then construct a final program out of AC recommendations, we are mindful of the dual role that a full-paper peer-review conference like COLING 2018 is playing.
On the one hand, peer review is meant to be an integral part of the process of doing science. If something is published in a peer-reviewed venue, that is an indication that it has been read critically by a set of reviewers and found to make a worthwhile contribution to the field of inquiry. This doesn’t ensure that it is correct, or even that most people up-to-date with the field would find it reliable, but it is an indication of scientific value. (This is all the more difficult in interdisciplinary fields, as we address some in an earlier blog post.) This aspect of peer review fits well with the interests of the conference audience as stake-holders: The audience benefits from having vetted papers curated for them at the event.
On the other hand, for individual researchers, especially those employed in or hoping to be employed in academia, acceptance of papers to COLING and similar venues is very important for job prospects/promotion/etc. Furthermore, it isn’t simply a matter of publishing in peer-reviewed venues, but in high-prestige, competitive venues. Where the validation view of peer review would view it as binary question (does this paper make a validatable contribution or not?), the prestige view instead speaks to ranking—where we end up with best papers, strong papers, borderline papers that get in, borderline papers that don’t get in, and papers that were easy to decide to reject. (And, for full disclosure, it is in the interest of a conference to strive to become and maintain status as a high-prestige, competitive venue.)
While understanding our role in the validation aspect of peer review, we are indeed viewing it as a ranking rather than binary process, for several reasons. First, the reviewers are also human, and it is simply not the case that any group of 3-5 humans can definitively decide whether any given paper (roughly in their field) is definitely ‘valid’ or ‘invalid’ as a scientific contribution. Second, even if we did have a perfect oracle for validity, it’s not the case that the amount of available spots in a given conference will be a perfect match for the number of ‘valid’ papers among the submissions. In case there are more worthy papers than spots, decisions have to be made somehow—and we believe that somehow should include both measures of degree of interest in the paper and overall diversity of approaches and topics in the program. (Conversely, we will not be aiming to ‘fill up’ a certain number of spots just because we have them.) Finally, we work with the understanding that COLING is not the only conference available, and that authors whose work is not accepted to COLING will in most cases be able to improve the presentation and/or underlying methodology and submit to another conference.
That ranking is ultimately binarized into accept/reject (modulo best paper awards) and we understand (and have our own personal experiences with!) the way that a paper rejection can seem to convey: ‘this research is not valid/not worthy.’ Or alternatively, that authors with relatively high headline scores on a paper that is nonetheless rejected might feel that the ‘true’ or ‘correct’ result for their paper was overridden by the ACs or PC. But we hope that this blog post will help to dispel those notions by providing a broader view of the process.
PC process once we have the AC reports
Once the ACs provide us with their rankings and reports, on May 4, we (PC co-chairs) will have the task of building from them a (nearly) complete conference program—the one outstanding piece will be the selection of best papers from among the accepted papers. Ahead of time, we have blocked out a ‘frame’ for the overall program so we have upper limits on how many oral presentations and poster presentations we can accept.
As a first step, we will look to see how the total acceptance recommendations of the ACs compares to the total number of spots available. However, it is not our role to simply accept the AC’s recommendations, but rather to review them and ensure that the decisions as a whole are consistent (to the extent feasible, given that the whole process is noisy) and that the resulting program meets our goals of diversity in regard to topics and approaches (again, to the extent feasible, given the submission pool). We have also asked ACs to recommend mode of presentation (oral, poster), with the understanding that oral presentations are not ‘better papers’ than posters, but rather that some topics are more likely to be successful in each mode of presentation.
Though the author identities have been hidden from ACs, they haven’t been hidden from us. Nonetheless, as we work with the AC reports, we will have paper numbers & titles (but not author lists) to work from and will not go out of our way to associate author identities. Furthermore, the final accept/reject decisions for any papers that either of us have a COI with will be handled by the other PC co-chair together with the conference GC.