How was your COLING experience? Please, let us know through this post-event survey.
COLING post-conference survey
9

How was your COLING experience? Please, let us know through this post-event survey.
Here is a list of sessions and chairs for the main conference:
by Nanna Inie, researcher and practitioner in Digital Design at Aarhus University.
PRESENTING YOUR ACADEMIC WORK AT A CONFERENCE – applicable tips and advice
Everybody likes a good conference presentation. It is your chance to catch the interest of a room of interested peers that might cite your work and help spread it for you. Whether you are presenting a talk or a poster, you have the opportunity to sprout the interest of those conference attendees that just accidentally happened to be there because you were co-located with a talk or poster they actually came to see.
Perhaps even more importantly, you also take upon yourself the risk of boring the living hell out of those attendees that chose to give you just a little bit of their most valuable resources: their time and attention. That is something to be respectful of.
In this post I would like to share some applicable tips for presentations – both oral and posters. While academia is certainly a distinct communication genre with its own merit, and conference talks should not aim to be TED talks or advertising campaigns, there are some key rhetorical and visual strategies that would improve most academic presentations. After all, your goal is to convince your audience that your work is trustworthy, thorough, and above all interesting, so anything that might make that conclusion easier for them is a win for you.
PRESENTING YOUR WORK WITH TALKS AND SLIDES
Structure is everything, and the general rule is to keep the introduction to taking up 10% of your speech, content 80%, and conclusion 10%. The next general rule is to relate everything you include in your speech structure to one single purpose. That does not mean you can not tell stories about your data or your experiments, but only if they contribute to exemplifying the point you are trying to make.
As an academic, you are lucky enough to have already written the content you are trying to communicate – but your presentation should not just be a summary of your paper. It should be better – more appetizing – you have the time to focus on the really juicy parts of your results. Unless related work is literally a cornerstone of your contribution – is it necessary for your point? Ask for every single piece of information you put in your talk: would the talk suffer if I took this out? What does it contribute to the purpose? And is there a way I could amplify its contribution to the point – even if this means repeating why you are including this information to your audience.
Your first step is to decide which one core message you would like the audience to leave your talk with. If they forget everything else, what is the one sentence you want them to remember (except from “cite my work”)? It’s probably in your conclusion somewhere, but you might find it in the discussion, the results or even your research question. Once you have decided what your main purpose of the talk is, you can start building your talk around it. Here are 5 applicable tips for how to get your message across in a confident, convincing way:
1. Use crescendo. Keep the audience’s attention throughout your speech by building to a climax, rather than peaking too soon. Conference talks are quite short, and this works to your advantage. The audience barely has time to get bored. If you peak their interest early, they barely have time to fade away before your point can be made (NB: starting off with presented related work is not peaking your audience’s interest!). Once you have made it to your point, end quickly. For a short example of a talk that does this brilliantly, I refer you to this TED-talk “How to start a movement” by Derek Sivers (https://www.ted.com/talks/derek_sivers_how_to_start_a_movement). In this talk, Derek Sivers manages to tell his story, exemplified by a video recording in real time, and it works perfectly as a crescendo building the audience’s interest in “What on earth is this going to lead to?”. Once the video has ended, he recaps his points using no slides, ending quickly thereafter.
2. Pick a narrative structure. This will help your speech to be more memorable to your audience. Here are 3 of the most common speech narratives (there are many forms, but these are applicable to most academic presentations):
The Tower Structure: This is how many academic talks are structured. You use bits and pieces of information (which are interesting to the audience) to build your argument. Once you have finished this structure, you can show the audience the power of the totality of the argument you have created.
Mystery Structure: The mystery structure is about presenting a problem or question to your audience that they are desperate to know the answer to. You want to keep them in the dark throughout your talk for this structure, not revealing the answer until the very end. You might present hints and clues to the solution along the way, including the audience in your journey towards your crucial message.
Ping Pong Structure: The ping pong structure is ideal if you expect the audience to contradict your point. In this structure you present both sides of the argument, one after another, in such a way that the audience can follow both sides and stay curious about which side ultimately wins.
3. Consider adding pauses rather than additional information. Pauses are as powerful as white space in posters. If you have noticed, almost all TED talks that use slides work with “break slides” – deliberately empty slides that leave the screen black and forces the audience’s attention back to you. If you are building your argument and want to add that little extra weight on a sentence, consider either using a 4-5 second long pause after your sentence (5 seconds can feel like an eternity when you are presenting, but to the audience it is just enough time to let the argument sink in) – perhaps even repeat the argument again in a slightly different way after your pause. You might want to consider leaving your screen without slides for the introduction of your talk, to make sure you have the audience’s undivided attention, or leaving some slides black when you want to explain something technical that needs audience concentration.
4. Support with slides, don’t explain. That brings us to a little discussion about slides. Slides can be fantastic and they can be awful. They can support and they can distract, depending on how they are used. You have probably heard about keeping your slides to only bullets before. It’s still true. But it doesn’t necessarily solve anything – as it turns out, bullets can be just as long and text heavy as normal sentences. Do you actually need slides to present your work? I would like to pose that you don’t – unless you have visual material that highly underpins your crucial point. Models, images, graphs. Other than that, slides should not really be necessary. If you would like to use slides, use them to support the audience, not to support you. That’s what your notes are for. There is nothing wrong with writing your key message on a slide so your peers can photograph and tweet it, but then think about: what would your peers consider worth tweeting? And make it fun – don’t be afraid to add living images or videos (check the sound though), especially of your data. It is always fun to see the data – even if your data is a program, consider doing a screencast of it running and adding that as a silent video in the background while you explain what is cool about it.
5. Stay enthusiastic. If you do not think your results are fun and interesting, chances are your audience won’t either. Try your very best to identify exactly what made you interested in this problem originally, and convey that to your audience. Sometimes that involves explaining how your results might be used in the future – I have sometimes taken the liberty to add slides that were just called “Imagine a thing that …” and used that to explain how my results could be transformed into systems that would change the world. Sometimes illustrated by less than perfect stick figure illustrations – but the point here is not to show off as a designer, but to show the audience that I really, really want to tell them how fantastic this system could be – even if I couldn’t draw it very well.
HOW TO PRESENT WITH POSTERS
The number one mistake academic posters make is cramming in too much information on a piece of paper. Depending on how your (published) paper is written, your poster often does not need more information than is in the conclusion section:
That’s it. Most of these should be explainable in 1-3 bullet points of one-two sentences each, not much more. If your poster is based on a paper, you can print out copies of the paper and keep those next to the poster, so that interested parties can grab one.
Layout
People from left to right language systems read from left to right and top to bottom, which is how you have to help them digest the information you would like to present. Clearly defined boxes makes it easier for the eye to navigate the poster, especially in a horizontal (landscape) layout. Boxes do not have to be defined by borders (in fact, if you do not know what you are doing, I highly advise against using borders), but can be created by background colors or even white space. When you design posters, white space or negative space should be your new best friend – at least 40% of the poster should be free of text. This will make the text that did make the cut come much more into focus.
Consider highlighting your most interesting points with a colored box and white text, as for the title and conclusion below (notice how the other text seems “boxed” by white space but without actually having borders):
 In my opinion, if you are not using a proper layout program (like Adobe InDesign), don’t be afraid of using tables to help you get that alignment right. It is much better to keep the layout conservative and maintain proper alignment than it is to experiment too much and end up with boxes that are a couple of centimeters off because PowerPoint just wants to watch the world burn. In the image above, I have just created one big table with three vertical columns, merged the two top left cells and, most importantly, adjusted the cell padding (the space, in pixels, between the cell wall and the cell content) to be high, thus automatically getting that nice white space.
In my opinion, if you are not using a proper layout program (like Adobe InDesign), don’t be afraid of using tables to help you get that alignment right. It is much better to keep the layout conservative and maintain proper alignment than it is to experiment too much and end up with boxes that are a couple of centimeters off because PowerPoint just wants to watch the world burn. In the image above, I have just created one big table with three vertical columns, merged the two top left cells and, most importantly, adjusted the cell padding (the space, in pixels, between the cell wall and the cell content) to be high, thus automatically getting that nice white space.
Finally, don’t underestimate the power of an attention-grabbing poster. In the poster below, the concept of “long tail” was translated into a lemur, giving an opportunity to use a really big picture of a cute animal. Cheap trick as it might be, it actually does attract people’s attention, and if you are hanging out by your poster for a couple of hours anyway, you might as well not do it alone.

Other techniques can make a poster attractive. There two below are made of wood; the first is interactive, and one should turn round sections of it to reveal information. The second can be rearranged, connected with velcro – but the novel medium is enticing in itself.


Graphic resources
If you wish to upgrade the visuals of your poster, I highly recommend looking into three elements: images, icons, and fonts. I’ve added three resources for these that are free and easy to use:
Photos: https://www.pexels.com/
Gorgeous, free stock photos that will make your slides or posters so much more appealing
Icons: Looking for simpler illustrations? https://www.flaticon.com/categories is your friend!
Fonts: Sans-serif is generally better looking on screens and for headlines. https://www.fontsquirrel.com/ has many beautiful, free fonts – if you just need something that works quickly, you can’t go too wrong with Open Sans, Helvetica Neue or Rubik – bold for headlines and light or normal for body text.
Best of luck for your presentation!
 Nanna Inie is finishing up a PhD in Digital Design at Aarhus University. As well as being founder of the largest TEDx event in Denmark, Nanna has previously been acclaimed with audience favorite poster at CHI during a stay at the UCSD Design Lab, and owns a video production company.
Nanna Inie is finishing up a PhD in Digital Design at Aarhus University. As well as being founder of the largest TEDx event in Denmark, Nanna has previously been acclaimed with audience favorite poster at CHI during a stay at the UCSD Design Lab, and owns a video production company.
Here is the list of papers accepted at COLING 2018, to appear in Santa Fe. This list was delayed until the best paper process was completed, to make sure that these awards were selected without committee members being able to know the identity of paper authors.
Congratulations to all authors of accepted papers; we look forward to seeing you in New Mexico!
There are multiple categories of award at COLING 2018, as we laid out in an earlier blog post. We received 44 nominations for best papers over ten categories, and conferred best paper awards in the categories as follows:
Note that, as announced last year, for open science & reproducibility COLING 2018 did not confer best paper awards to paper that could not make the code/resources publicly available by camera ready time. This means you can ask the best paper authors for associated data and programs right now, and they should be able to provide you with a link.
In addition, we would like to note the following papers as “Area Chair Favorites”, which were nominated by reviewers and recognised as excellent by chairs.
We would like to recognise with exceptional thanks our best paper committee.
So far, there have been many things to measure of our review process at COLING. Here are a few.
Firstly, it’s interesting to see how many reviewers recommend the authors cite them. We can’t evaluate how appropriate this is, but it happened in 68 out of 2806 reviews (2.4%).
Best paper nominations are quite rare in general. This gives very little signal for the best paper committee to work with. To gain more information, in addition to asking whether a paper warranted further recognition, we asked reviewers to say if a given paper was the best out of those they had reviewed. This worked well for 747 reviewers, but 274 reviewers (26.8%) said no paper they reviewed was the best of their reviewing allocation.
Mean scores and confidence can be broken down by type, as follows.
| Score | Confidence | |
| Computationally-aided linguistic analysis | 2.85 | 3.42 |
| NLP engineering experiment paper | 2.86 | 3.51 |
| Position paper | 2.41 | 3.36 |
| Reproduction paper | 2.92 | 3.54 |
| Resource paper | 2.76 | 3.50 |
| Survey paper | 2.93 | 3.58 |
We can see that reviewers were least confident with position papers, and were both most confident and most pleased with survey papers—though reproduction papers came in a close second in regard to mean score. This fits the general expectation that position papers are hard to evaluate.
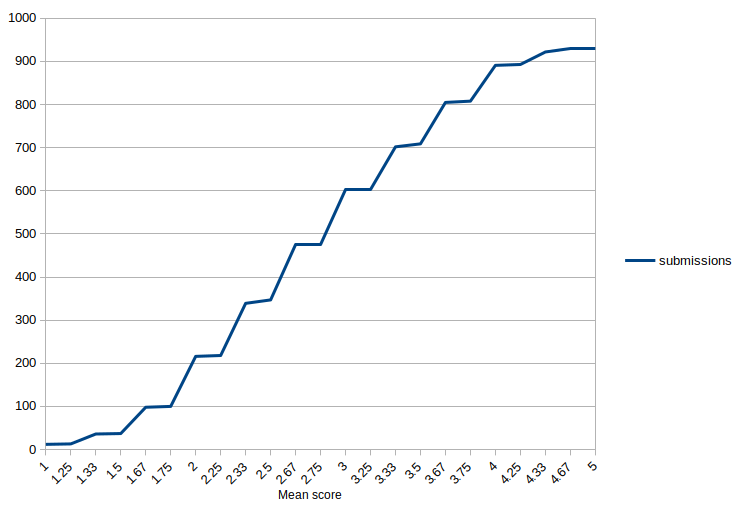
The overall distribution of scores follows.
Anonymous review is a way of achieving a fairer process. The ongoing discussion among many in our field led to us examining how well this was really working, and rethinking how anonymity was implemented for COLING this year.
One step we took was to make sure that area chairs did not know who the authors were. This is important because area chairs are the ones putting forward recommendations based on reviews; area chairs are the people who mediate between borderline papers and acceptance, or who assess reviewer ratings to decide if they put a paper on the wrong side of the acceptance boundary. This is a critical and powerful role. So, we should be extra sure that if a venue has chosen to run an anonymized process, the area chairs don’t see paper authors’ names.
This policy caused a little initial surprise but everyone has adapted quickly. In order for this to work, authors must continue to hide their identity, especially through author response to chairs—the current process.
We also increased anonymity in reviewer discussion: reviewers did not and still do not know each others’ identity. To keep review tone professional, we will reveal reviewer identities to each other later in the process, so if you are one of our generous program committee members, you can see who perhaps wrote the excellent review you saw, and also who left the blank one—on submissions you also reviewed.
It’s established that signed reviews—that is, those including the reviewer’s name—are generally found by authors to be of better quality and tone. We gave an option to reviewers to sign their reviews. This time, 121 reviewers used this, out of 1020 active review authors (11.9%).
On the topic of anonymity, there have been a few rejections due to poor or absent anonymization. To help future authors, here are some ways anonymity can be broken.
Some of these can be avoided by simply only referring to one’s past literature in the camera-ready copy, and holding back for review, which is a strategy we recommend. Of course it’s not always possible, but in most of cases we saw, refraining from self-citing would not have damaged the narrative and would have left the paper compliant.
The final step in the review process, from the author side, is author response to chairs. Please remember to keep yourself anonymous here—the chairs know neither author nor reviewer identities, which helps them be impartial.
We’ve had a successful COLING so far, with over a thousand papers submitted, covering a variety of areas. In total, 1017 papers were submitted to the main conference, all full-length.
Each submitted paper had a distinct type assigned by the authors, that affects how it is reviewed. These were developed based on our earlier blog post on paper types. The “NLP Engineering Experiment paper” was unsurprisingly the dominant type, though only made up for 65% of all papers. We were very happy to receive 25 survey papers, 31 position papers, and 35 reproduction papers—as well as a solid 106 resource papers and a strong showing of 163 computationally-aided linguistic analysis papers, the second largest contingent.
Some papers were withdrawn or desk rejected before review began in earnest. Between ACs and PC co-chairs, in total, 32 papers were rejected without review. Excluding desk rejects, so far 41 papers have been withdrawn from consideration by the authors.
Allocating papers to areas gave each area a mean and median of 27 papers. The largest area has 31 papers and the smallest 19. We interpret this as indicating that area chairs will not be overloaded, leading to better review quality and interpretation.
At COLING 2018, we require submitted work to follow the Vancouver Convention on authorship – i.e. who gets to be an author on a paper. This guest post by Željko Agić of ITU Copenhagen introduces the topic.
One of the basic principles of publishing scientific research is that research papers are authored and signed by researchers.
Recently, the tenet of authorship has sparked some very interesting discussions in our community. In light of the increased use of preprint servers, we have been questioning the *ACL conference publication workflows. These mostly had to do with the peer review biases, but also with authorship: Should we enable blind preprint publications?
The notion of unattributed publications mostly does not sit well with researchers. We do not even know how to cite such papers, while we can invoke entire research programs in our paper narratives through a single last name.
Authorship is of crucial importance in research, and not just in writing up our related work sections. This goes without saying to all us fellow researchers. While in everyday language an author is simply a writer or an instigator of a piece of work, the question is slightly more nuanced in publishing scientific work:
These questions have sparked many controversies over the centuries of scientific research. An F. D. C. Willard, short for Felis Domesticus Chester, has authored a physics paper, similar to Galadriel Mirkwood, a Tolkien-loving Afgan hound versed in medical research. Others have built on the shoulders of giants such as Mickey Mouse and his prolific group.
Yet, authorship is no laughing matter: It can make and break research careers, and its (un)fair treatment can make a difference between a wonderful research group and an uneasy one at the least. A fair and transparent approach to authorship is of particular importance to early-stage researchers. There, the tall tales of PhD students might include the following conjectures:
The curiosities and the conjectures listed above all stem from the fact that there seems to be no awareness of any standard rulebook to play by in publishing research. This in turn gives rise to the many different traditions in different fields.
Yet, there is a rulebook!
One prominent attempt to put forth a set of guidelines for determining authorship are the Vancouver Group recommendations. The Vancouver Group are the International Committee of Medical Journal Editors (ICMJE), who in 1985 introduced a set of criteria for authorship. The criteria have seen many updates over the years, to match the latest developments in research and publishing. Their scope far surpasses the topic of authorship, and spans across the scientific publication process: reviewing, editorial work, publishing, copyright, and the like.
While the recommendations do stem from the medical field, they are nowadays broadened and thus widely adopted. The following is an excerpt from the recommendations in relation to authorship criteria.
The ICMJE recommends that authorship be based on the following 4 criteria:
1. Substantial contributions to the conception or design of the work; or the acquisition, analysis, or interpretation of data for the work; AND
2. Drafting the work or revising it critically for important intellectual content; AND
3. Final approval of the version to be published; AND
4. Agreement to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.
(…)
All those designated as authors should meet all four criteria for authorship, and all who meet the four criteria should be identified as authors. Those who do not meet all four criteria should be acknowledged.
(…)
These authorship criteria are intended to reserve the status of authorship for those who deserve credit and can take responsibility for the work. The criteria are not intended for use as a means to disqualify colleagues from authorship who otherwise meet authorship criteria by denying them the opportunity to meet criterion #s 2 or 3.
Note that there is an AND operator tying the four criteria, but there are some ORs within the individual entries. Thus, in essence, to be adherent with the Vancouver recommendations for authorship, one has to meet all four requirements, while in meeting each of the four, one is allowed to meet them minimally.
To take one example:
If you substantially contributed to 1) data analysis, and to 2) revising the paper draft, and then you subsequently 3) approved of the final version and 4) agreed to be held accountable for all the work, then congrats! you have met the authorship criteria!
One could take others routes through the four criteria, some arguably easier, while some even harder.
In my own view, we as a field should hope for the Vancouver recommendations to have already been adopted in NLP research, if only implicitly through the way our research groups and collaborations work.
Yet, are they? What are your thoughts? In your view, are the Vancouver recommendations well-matched with the COLING 2018 paper types? In general, are there aspects of your work in NLP that are left uncovered by the authorship criteria? Might there be at least some controversy and discussion potential to this matchup? 🙂
As the deadline for submission draws near, we’d like to alert our authors to a few things that are a bit different from previous COLINGs and other computational linguistics/NLP venues in the hopes that this will help the submission process go smoothly.
Please consider the paper type you indicate carefully, as this will affect what the reviewers are instructed to look for you in your paper. We encourage you to read the description of the paper types and especially the associated reviewer questions carefully. Which set of questions would you most like to have asked of your paper? (And if reading the questions inspires you to reframe/edit a bit to better address them before submitting, that is absolutely fair game!)
Emiel van Miltenburg raised the point on Twitter last week that it can be difficult to categorize papers and in particular that certain papers might fall between our paper types, combining characteristics of more than one, or being something else entirely.
We had a very nice discussion at @CLTLVU today about papers we’re planning to submit to @coling2018.
Everybody agreed that the paper types are very useful, but it’s sometimes difficult to categorize #nlproc papers.
— Emiel van Miltenburg (@evanmiltenburg) March 7, 2018
Emiel and colleagues wondered whether we could implement a “tagging” system where authors could indicate the range of paper types their paper relates to. That is an intriguing idea, but it doesn’t work with the way we are using paper types to improve the diversity and rage of papers at COLING. As noted above, the paper types entail different questions on the review forms. We’re doing that because otherwise it seems that everything gets evaluated against the NLP Engineering Experiment paper type, which in turn means it’s hard to get papers of the other types accepted. And as we hope we’ve made it blindingly clear, we really are interested in getting a broad range of paper types!
The other aspect of our submission form that will have a strong impact on how your paper is reviewed is the keywords. Following the system pioneered by Ani Nenkova and Owen Rambow as PC co-chairs for NAACL 2016, we have asked our reviewers to all describe their areas of expertise along five dimensions:
(All five of these have a none of the above/not-applicable option.) The reviewers (and area chairs) all indicated all of the items on each of these dimensions they have the expertise and interest to review for. For authors, we ask you to indicate which items on each dimension best describe the paper you are submitting. Softconf will then match your paper to an area based on the assignment of papers to areas that best optimizes reviewer expertise for the papers submitted.
In sum: To ensure the most informed reviewing possible of your paper, please fill out these keywords carefully. We urge you to start your submission in the system ahead of time so you aren’t trying to complete this task in a hurry just at the deadline.
Our Call for Papers indicates the following dual submission policy:
Papers that have been or will be under consideration for other venues at the same time must indicate this at submission time. If a paper is accepted for publication at COLING, it must be immediately withdrawn from other venues. If a paper under review at COLING is accepted elsewhere and authors intend to proceed there, the COLING committee must be notified immediately.
We have added a field in the submission form for you to be able to indicate this information.
COLING 2018 is participating in LRE map, as described in this guest post by Nicoletta Calzolari. In the submission form, you are asked to provide information about language resources your research has used—and those it has produced. Do not worry about anonymity on this form. This information is not shared with reviewers.